基于虎扑数据的中美篮球运动员热度统计
1. 前言
在互联网这个汪洋大海中,有一个网站叫虎扑,据称“可能是最好的篮球网站”。虎扑以“湿乎乎板块”为核心,集聚了大量的篮球运动爱好者。就像“湿乎乎”的字面意思一样,虎扑里时不时会因为热点实现事件、话题掀起海啸一般的唾沫星子——这都是JRs争论时喷出来的。以前,这个网站里有很多清凉图片,年少的我每天逛得乐不思蜀。后来,虎扑好像要做个好人,主要呈现体育运动相关相关信息,没有啥刺激性内容了。
作为一个老JR,我在开放区、步行街、湿乎乎潜行十几年,发现大家最喜欢的话题,莫过于“谁是最XX的”。假如说,我发一个帖子问“姚明是当时最厉害的中锋吗”,估计58秒内会有4000个JRs提着40米的大刀前来发言。“最XX”的话题中,最让人欲罢不能的,当属“谁是最红的巨星”、“谁是篮球界的门面”这类讨论。由于大家没有具体的数据,只能凭感觉比较或者基于简介数据来佐证,这种讨论没办法得出令所有人性福的结论。
作为一个做NLP算法的JR,我利用手上的技能和工具,对虎扑最近若干个月的所有帖子(各大板块的3160340个主贴和128162300个跟帖)进行了简单的统计,试图给大家伙一个参考。我是这么做的:识别所有帖子中的人名,并统计每个人名的出现次数,然后直接以名字的频数作为对应球员的热度。这里使用的NER和分词算法都来自阿帕比技术公司开发的NLP工具包。
本文的主要内容是:首先介绍文本的目的和意义;然后直接给出结论,即谁是最火的篮球运动员;接着介绍从数据获取到得出结论的整个过程,包括必要的软件系统设计与开发、数据的基本情况和数据统计的具体方法,以说明结论的合理性。
2. 目的和意义
我做这个分析的首要目的,是想调查一下,中国男子职业篮球联赛(China Basketball Association, CBA)在国内的受众广度。另外,我也想知道CBA的发展阶段,比如相比NBA,其受众广度的大小。这是好奇心驱动的一个项目。
其次,在这个过程中,把数据采集、目标范围定义、数据清洗、建模、可视化等等环节——都玩耍一下。是的,工作一般来说比较枯燥,各种形式的玩耍可以调剂一下。
再次,我需要一个形式,把目前的思维方式、方法论、技术水平等等记录下来,以便以后复盘和优化。
最后,这种分享行为是学术公益活动的一种,可以帮很多需要入门的人避免踩坑。
3. 谁是虎扑篮球热度南波万
在虎扑,谁是最火的篮球运动员?是无极尊吗?废话少说,先上结论。
3.1. 中美篮球职业篮球运动员热度排行榜
3.1.1. 中美明星球员热度比较
如表3-1,是中国职业男子篮球联赛和美国职业男子篮球联赛本赛季注册运动员的热度排行前20名(可视为中美篮球明星)。中美篮球明星榜被美职篮球员统治了——只有4位CBA球员进入了这个榜单,他们是新疆飞虎队的周琦、广东华南虎队的易建联、辽宁飞豹队的郭艾伦和北京鸭队的林书豪。
表 3-1中美现役篮球运动员热度排行top 20

从明星球员的公司情况可以看出,在虎扑网,中职篮明星球员的热度大幅度地低于美职篮明星球员。按理说,虎扑作为一个中文体育网站,是我们的主场,中职篮应该向朱芳雨一样,轻轻松松“一拳打开了天”,如图3-1。实际情况是,美职篮依靠其更高的经济水平和观赏性,以及更高的运营和推广能力,统治了我们的主场。中职篮产生流量的能力水平其实是比较菜的,类似图3-2。
3.1.2. 中美普通球员热度比较
篮球是一项集体运动,不只有璀璨的明星,更多的是普通球员。在中美的普通球员之间,有没有类似明星球员那样的热度差距呢?如图3-3,是中职篮和美职篮球员热度的箱型图。由于普通球员的热度相对明星球员非常低,我的“箱子”被压得非常扁,肉眼看不出来最广大人民的情况。
这时候,我们可以用直方图来分析一下。如图3-4,有4个子图,其中左边一列是中职篮和美职篮全体球员的热度直方图。我又截取了两个联盟里热度值小于等于90分位数的球员数据,形成了图3-4里右边一列子图。
图3-4左边一列子图告诉我们,中职篮和美职篮都是明星当道,少数高水平球员产生了绝大部分的热度。剩下的都是默默无闻的普通球员。注意右边一列子图横轴的取值范围,中职篮的普通球员热度,比美职篮的普通球员热度低了一个数量级。
看来我们和人家的差距,是全方位的。
总的来说,我国运动员的热度,在一个国内网友为主的论坛里,是低于美职篮运动员的。
3.2. CBA人物热度榜
如表3-2,是中职篮球员的热度排行。我已经多年不看球了,这个榜单中的一小部分名字不熟、大部分球员不熟,只挑几个熟悉的说说。周琦在CBA球员中的领先优势,比“美国周琦”在NBA球员中的领先优势要大得多。易建联、孙悦、周鹏这几个老家伙,依然具有明星级别的热度。其中易建联依靠不懈的努力,依然具有顶尖的竞技水平。 林书豪作为当年在NBA的“黄人之光”,受到了极高的关注。到了CBA,他直接成为联盟里最火热的球星。从这里也能看出我们的联赛,在推广方面,可以提升的空间还是很大的。小霸王斯塔德迈尔依靠在美职篮的野兽派+技术流打法,有着不错的人气,也进入了前20。
有个现象还是挺好的。这里绝大部分是我们的本土球员,说明大家关注的,主要还是自己人。不论水平如何,咱们对国内球员的支持还是一如既往,希望依靠自己人来提升我国篮球的竞技水平。
中职篮和美职篮这两个商业体育赛事的热度,主要还是靠明星球员来产生。人们围绕这些明星球员创作了各种各样的概念和梗,让体育比赛更有故事性、从而进入球迷的茶余饭后。作为一个产品,体育赛事的用户粘性也就得到了提升。中职篮要加油了,我们的比赛、球员水平需要提升,让球迷们感觉这是个具有美感的体育赛事;也需要用球队文化、故事之类的东西包装一下我们的球员,让他们可以成为球迷们口头禅的一部分。
表 3-2 中职篮球员热度排行top20
3.3. NBA人物热度榜
如表3-3,是美职篮球员热度排行榜。老詹球场上实力超群,场下也是“流量皇帝”,热度值大幅领先于他的同事。据我所知,在湿乎乎里随便发一个关于老詹的帖子,就可以收割曝光量了。雷霆三兄弟不光都成为了了最有价值球员,还都成了最具热度球员。三弟的排行超过了大哥,看来好平台的作用还是非常大的。莱昂纳德依靠高超的技艺,和最近几年的争议性事件,也积累了极高的人气,竟然能排在威少的前面,把雷霆仨兄弟给分开。
这里有一个比较明显的问题,就是金州勇士队的库里没有进入top20。他的热度竟然排在了第76位,不寻常。主要原因是我的球员名字数据库构建的不完整,没有收录类似“库日天”“库昊”“小学生”“金州拉文”“萌库”这样的别称。众所周知,库里的球迷特别喜欢为库里其各种各样的绰号,比如用“库日天”来表达对库里精湛的投篮技术的赞美。漏掉了这些别称的后果,就是这位球员的热度被大大低估了。由于任务架构设计失误,没有保存人名抽取的中间结果,再算一遍的成本抬高,我这里就不重算啦。
表 3-3 美职篮球员热度排行top20
3.4. 特色球员简介
我发现了虎扑里流量最高的篮球运动员,是时候蹭一波热度了。这时候,我需要发挥比大师那种钻研精神,好好地研究一下他们。
说什么最吸引流量呢?当然是有争议性的话题。这里就选最具争议性的话题:球星的梗。
3.4.1. 流量皇帝勒布朗-詹姆斯
果然,詹姆斯在现役篮球运动员中,是热度最高的。
由于没有统计退役球员的数据,没有考虑乔丹、科比这样的流量达人,这里只能说“现役”。
如果这是篇学术论文,我会把詹姆斯的几十个绰号全都收录并展示出来。然而这是个“技术讨论贴”,不利于大家团结的内容就不展示了(一些极端球迷使用了不和谐的措辞,给詹姆斯起了大量涉及人身攻击的绰号),这里只展示围绕生活和篮球的部分绰号。
表3-4 詹姆斯的外号与梗
如图,我统计了老詹今年(实际是从2018年末开始,但是这个阶段的数据缺失太多)3月份以来,每一个周的热度情况。由于代码的bug,我的聚合操作,是按照“周五-下周四”这样的时间范围来做的。为了避免这几台机器的运转,造成我家气温继续上升,我决定不重算啦。统计的bug不影响曲线所要表达的内容。
今年湖人队没有进入季后赛,所以老詹的热度在相应时间段里比较低,和“长草期”差不多。七月份时,老詹的热度突然升高了一下。当时浓眉哥快要转会到湖人队,大家都在关注这支球队、讨论浓眉能否成功转会。十月中下旬开始,由于新赛季马上就要开始,老詹的热度一下就上来了。
可以说,球员的热度主要依靠比赛带来的曝光量来维持。
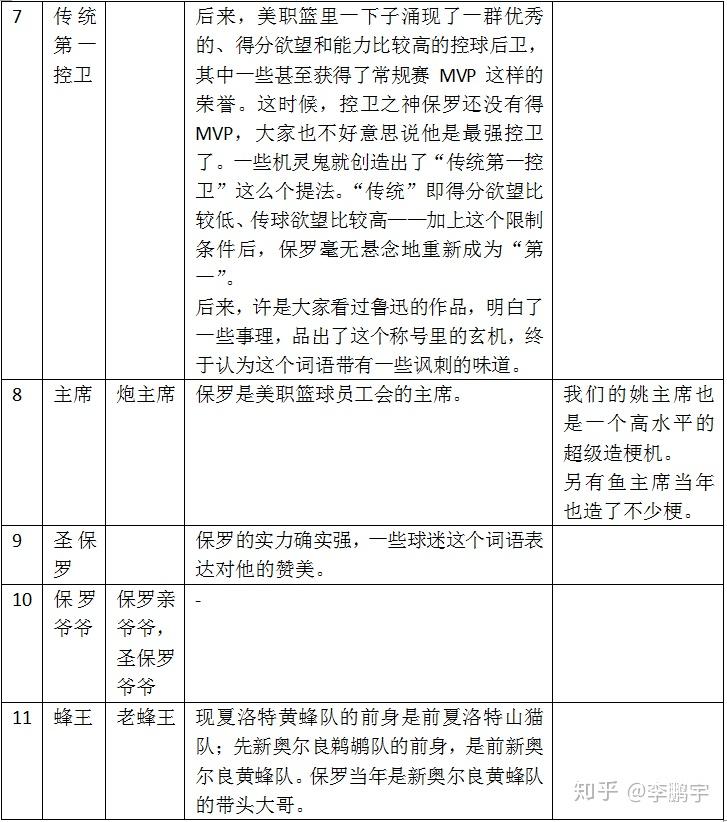
3.4.2. 男篮旗帜易建联
易建联是中国男篮历史上难得的一号人物,不论是国内比赛,还是国际比赛,都能火力全开。当然他从早期的一个身体素质男,一步步成长为后姚明时代的带头大哥,也是有一个过程的。
表 3-5易建联的外号和梗

3.4.3. 奇男子克里斯-保罗
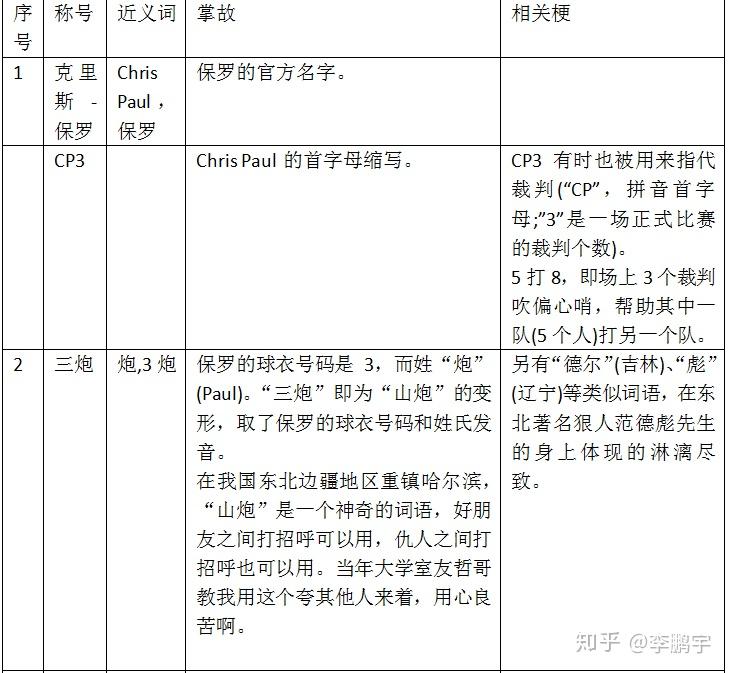
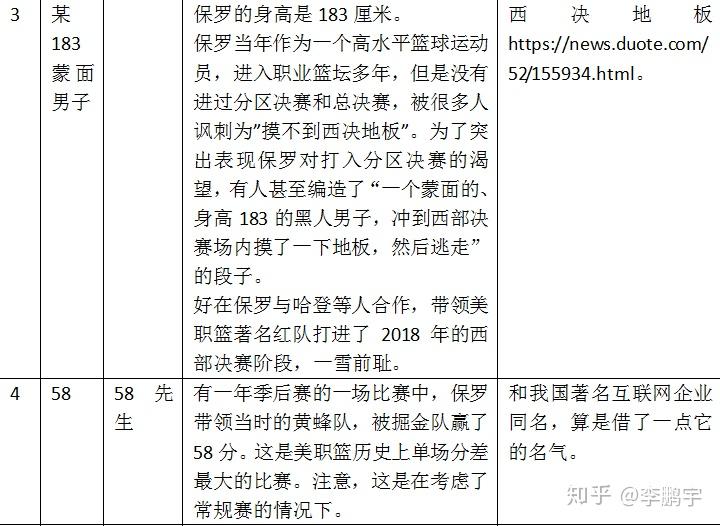
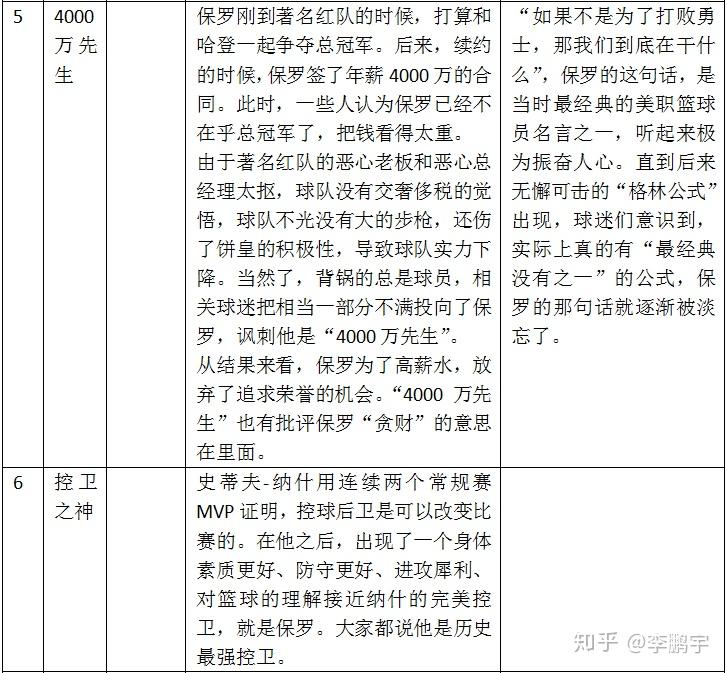
这位奇男子,如图3-6,在传奇的职业生涯里,积累了无数名号,如表3-6。如此之多的梗,足以体现广大球迷对保罗的关注程度之高。

表 3-6保罗的常见称号
4. 数据处理系统的设计和开发
知乎和虎扑都有点类似草榴社区的“技术讨论区”,没有干货的人是混不开的。接下来是方法和技术方面的干货。
4.1. 任务需求分析
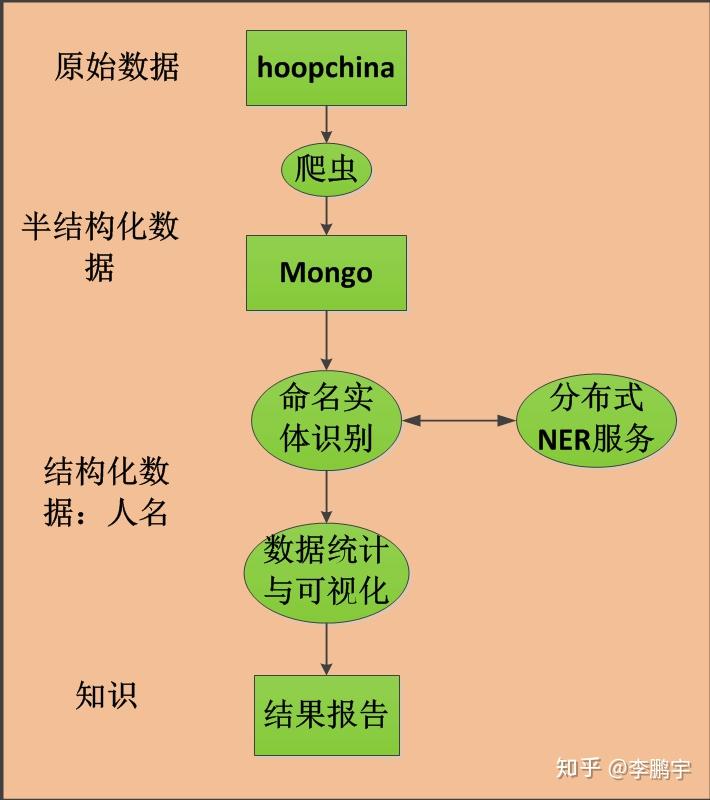
为了知道谁是虎扑篮球热度第一人,我需要一份虎扑数据,需要从数据中识别出命名实体并做简单的计数。为此,我需要3个工具:(1)一个用来获取虎扑帖子数据的爬虫;(2)一个用于从文本中抽取人的名字的工具;(3)一个用来对人名进行个数统计和可视化的工具。如图2-1,是用于完成任务的系统结构。
为了确保这个任务在可接受的时间内结束,我需要估计一下各个环节的耗时:
(1) 数据获取大概需要10天。这段时间里我可以开发调试命名实体识别环节和数据统计分析环节的代码,并完成报告的大纲和部分内容的撰写。
(2) 之后,就需要尽快完成命名实体识别任务。数据是2019年3月11日21点41分开始至XXXX的所有帖子,包括大约300万篇主贴加1.2亿回帖(平均每个帖子里的回帖数量大约是40),总共约1.23亿条数据。假设每条数据的处理速度是50毫秒,就需要两个月。这怎么行,都跨年了。必须想办法提升任务的并行度,降低耗时。
(3) 剩下的就是一个频率统计任务,也许3秒就够了。
4.2. 爬虫及获取虎扑数据概况
4.2.1. 爬虫
我是个野生的爬虫选手,无力开发一套高水平的爬虫,因此选择依靠开源框架。这里选择的是python的爬虫类第三方库中,最受欢迎的scrapy。
还在学校的时候,我花了超过一个月的时间开发了一个用来下载虎扑数据的爬虫。后来又对爬虫做了几次升级。然而2018年下半年,虎扑的页面数据结构发生了变动,我需要对爬虫进行大改。然而我是个打工仔,没有那么多的时间搞这个,只能作罢。后来听同事军伟大哥说,他基于scrapy开发爬虫可顺手了,于是我也调研了一下。果然是真香——过年的时候,我一边陪孩子玩,一边从零开始重写,不到一个礼拜就完工了。当然了,这里还需要感谢lxml这个库,它通过支持xpath语法,极大地减少了我们解析html的工作量。
爬虫的结构非常简单:获取数据,然后存到mongo中。由于不清楚分享爬虫代码算不算违法,代码就不分享了。
获取的数据包括两部分:帖子的主贴和对应的回帖。
4.2.2. 虎扑帖子文本数据基本情况
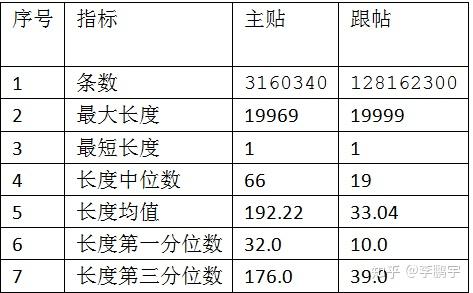
如表4-1,是爬虫获取到的数据概况。可能虎扑数据库的content字段类型为varchar,最大长度为19999,因此主贴和跟帖的最大长度接近或等于这个数。
主贴字数的中位数是66,说明大家发帖的时候,还是比较勤快的,为了阐述自己的想法或者疑问,愿意费一点口舌。
跟帖的字数中位数是19,说明JRs喜欢一句话解决战斗。据我目测,湿乎乎的网友说话很少能到这个字数。
表 4-1 数据获取结果概况
4.3. 命名实体识别工具
4.3.1. 选择一个合适的人名识别方法
文本中的人名识别,是命名实体识别任务的一种具体情形,可以使用NER的方法来实现。这是一个典型的计算密集型任务,最好使用Spark这样 分布式框架来处理数据量较大的情况。不过呢,我的Hadoop集群已经被自己弄坏了,恢复起来需要一段时间,修完也就跨年了。因此,这里使用了一个搭建
NER方案的制定过程说来话长,放在第5部分。
4.3.2. 用HTTP服务封装NER模型
前面提到,NER环节的耗时会非常长,需要想办法提升并行度。由于模型加载到内存里需要占大约500兆的内存,24G内存里最多放48个进程,也就是最快24小时可以完成计算——不过CPU核心数只有8,进程再多也没用。因此,我这个估算是极度乐观的,实际操作中的耗时肯定远远超过24小时,而且不可控。
为了保证任务耗时可控,我决定用一个简单的分布式架构来处理这些数据:在仅有的3台机器上部署NER服务,然后并发地、以一个设计好的概率分布调用集群。现在的资源是:24G+16G+8G=48G,8+12+24=44个CPU核心。这样,一秒钟可以处理约4500篇个文档,一天就是”2亿”,应该是够了。乐观情况下,半天计算完毕。如果实际情况不乐观,那就把家里的笔记本也加到集群里。分布式架构的可扩展性还是挺有帮助。
经过仔细优化的集群,实际用了8个小时就处理完全部数据。当时我家室内气温明显上升。
5. 人名识别方案
用来识别文本中的人名方法非常多,可以参考
统计人名频数任务看起来是最简单的任务,实际上是我花时间最多的一个环节。
我需要回答一个问题:如何判断文本中的一个字符串是否为人名。我的“答案”经过多次修改,终于成熟了。
当然,“真理”是值得追求的。在这个任务中,我只能在成本允许的情况下尽量接近他啦。
5.1. 初步的人名统计方法
一开始的时候,我选择的是一个基于神经网路的NER模型。使用神经网络的原因主要是两个:首先是我已经有一个成熟的NER模型了;其次,神经网络高级啊,说起来倍儿有面子。
这个模型是阿帕比技术公司自己开发NLP工具集中的一个模块,如果想体验这个模型,可以到这里看一下:
。这个模型对中文人名、音译人名的识别能力非常强,F1-score超过了0.9。由于训练语料里没有外文人名,我的模型无法识别“Yao Ming”这样的外文人名。这里选择忽略所有没有以中文表达的人名。这样做的损失是比较小的——虎扑里活跃的绝大部分人是中国人,极少使用外文来称呼一个人,比如我们很少称呼迈克尔-乔丹为“Jordan”(一般是乔丹、帮主、篮球之神、GOAT等)。
我用一份比较小的数据进行了人名统计。在看统计结果的时候,我发现机器找出来的人名中,绝大部分不是篮球运动员——难不成还要把这几百个人的频数挑出来?
这样做的成本有点高,而且万一数据处理流程有Bug、需要重新计算一遍,成本会更高。另外,基于神经网络的模型计算效率太低了,处理完整的数据集需要十几天。成本要爆炸了,不可行。
我得仔细琢磨一下这个场景,看看还有没有更好的选择。
5.2. 更好一点的统计方法
实际上,这个任务是一个典型的词语集合受控的场景:我只需要统计篮球运动员的名字,其他的可以采取类似多诺万教练的态度(可参考“我跟他不熟”)。这种场景非常适合使用基于词典的NER方法。
这样的话,我这个方案就简单了,需要解决两个问题:(1)人名词库的设计和建设;(2)找到文本与人名词库的匹配方法。
5.2.1. 篮球人物姓名数据库设计和构建
篮球运动员的个人资料非常好找:
CBA运动员信息的数据源为
NBA运动员信息的数据源是
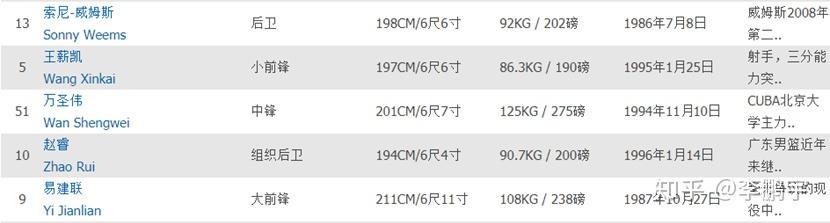
如图5-1,是虎扑网的球队信息中,球员部分。对中国球员,所有球员的姓名全称(比如“易建联”)收录到词库中,其中一部分我个人比较熟悉的球员配备了别称(比如“阿联”、“太空易”)。对外国球员,所有球员的姓名全称(例如”索尼-威姆斯”,“索尼威姆斯”)收录到词库,部分稀少、或不存在歧义的姓(比如“詹姆斯”通常指勒布朗-詹姆斯)作为对应球员的别称收录到词典,部分我个人比较熟悉的球员配备了尽量齐全的别称。
这个词典里实际上存在几种偏见:
(1) 首先,类似勒布朗-詹姆斯独占“詹姆斯”这个姓氏作为别称的做法,是对其他小众、姓氏同为“詹姆斯”的球员的不公平。这样做会把这些小众球员的一点数据转移到勒布朗-詹姆斯的身上,导致一种强者更强的结果。
(2) 我个人越熟悉的球员,具有越详尽的别称,可以以更高的查全率统计得到更精准的热度。其他球员的热度则或多或少地被低估了。
(3) 由于我个人的喜好,一些别称没有被收录到词库中,导致相关球员的热度值被低估了。黑粉也是粉嘛,带来的也是流量。
这两份数据已经整理为结构化数据,存储在excel文件中:
人名库构建的主要工作是球员别称的收集整理。在任务的过程中,首先基于领域知识,即对篮球运动员的了解,构建了人名数据库的字段,并添加了一部分别称;其次,基于那个用神经网络做的NER模型,找了一大堆人名,然后从中找了一些别称;另外,我又从论坛、搜索引擎里收集了一部分别称。
5.2.2. 人名匹配方法
按照直觉,我们可以使用子字符串匹配算法来统计人名,这样做起来简单。
不过呢,这样做会遇到严重的歧义问题。比方说,“我想叫姚明天过来给大家展示一下投篮”这句话中,“姚”这个字指的是姚明,“明天”是一个时间。如果使用自字符串匹配,我们就稀里糊涂的把“明天”拆开了。这个例子里只是碰巧对了。如何避免歧义的干扰呢?
我选择使用分词的方式,基于语言模型将文本切分为一个个小单元,然后与人名词库比对、找人名。语言模型可以基于对语法、语义的了解,把类似“姚明天”这样的字词精准切分开。这里使用了一个基于最短路径求解的马尔科夫模型分词工具(也是阿帕比技术公司的)。算法原理可以参考
6. 结束语
至此,这个由好奇心驱动的项目就告一段落。
马上就要过春节了,这里提前送上对所有人的祝福,如图6-1。

注意:本文为李鹏宇(知乎个人主页https://www.zhihu.com/people/py-li-34)原创作品,受到著作权相关法规的保护。如需引用、转载,请注明来源信息:(1)作者名,即“李鹏宇”;(2)原始网页链接,即当前页面地址。如有疑问,可发邮件至我的邮箱:lipengyuer@126.com。